
Ricardo V. C. Fernandes, Sydnei M. Gomes, Marcos V. Mantovani, Stephannie L. A. P. Chiang Ozawa, Daniel E. Gome
A plataforma NeoLabsAI nasce de uma constatação técnica e regulatória bem delimitada: o arcabouço brasileiro de Prevenção à Lavagem de Dinheiro e Combate ao Financiamento do Terrorismo ...
Plataforma NeoLabsAI de Inteligência e Explicabilidade Regulatória
Ricardo V. C. Fernandes
Pós-doutor em Inteligência Artificial Juridixa pelo CODEX-The Stanford Center for Legal Informatics.
Idealizador e coordenador do VICTOR Project, a IA do STF.
Doutor em Direito pela UnB.
Strategic AI Researcher da NeoLabsAI
Sydnei M. Gomes
Especialista em Inteligência Artificial, Engenharia de Software e Infraestrutura.
Bacharel em Gestão da Tecnologia da Informação pela Universidade Católica de Brasília.
AI Engineering Director da NeoLabsAI
Marcos V. Mantovani
Graduando em Análise e Desenvolvimento de Sistemas pela UNINTER.
Líder Técnico de Inteligência Artificial da NeoLabsAI
Stephannie L. A. P. Chiang Ozawa
Especialista em Engenharia de dados, pipelines escaláveis e arquiteturas de Big Data.
Bacharel em Engenharia de Computação pela Universidade de Brasília.
Engenheira de Pipelines Sênior da NeoLabsAI
Daniel E. Gomes
Especialista MBA em estruturas de Big Data.
Bacharel em Direito pelo Centro Universitário de Brasília.
Technical AI Researcher da NeoLabsAI
27 de Maio de 2026
Introdução
A plataforma NeoLabsAI nasce de uma constatação técnica e regulatória bem delimitada: o arcabouço brasileiro de Prevenção à Lavagem de Dinheiro e Combate ao Financiamento do Terrorismo (PLD/CFT) — sustentado pela Lei nº 9.613/1998, pela Circular BACEN nº 3.978/2020, pela Resolução BCB nº 50/2020 e pelas tipologias publicadas pelo Conselho de Controle de Atividades Financeiras (COAF) — exige das instituições financeiras três capacidades simultâneas que raramente convivem na mesma plataforma: detectar operações suspeitas em escala, explicar juridicamente cada decisão e documentar a trilha probatória de forma auditável. Direcionado especificamente para o mercado de investment banking e wealth management, o sistema foi projetado para solucionar o problema crítico da opacidade de contrapartes, respondendo em tempo de quase-realidade a questionamentos complexos sobre a identidade dos beneficiáriosf inais (UBO) e os riscos regulatórios associados a holdings interpostas ou estruturas societárias dissimuladas.
O desenvolvimento da plataforma reflete a tradição acadêmica e institucional de sua equipe de engenharia, que carrega herança direta de pesquisas de fronteira em inteligência artificial jurídica — incluindo o Projeto VICTOR, primeiro sistema de IA aplicado a uma Suprema Corte no mundo, desenvolvido em parceria entre o Supremo Tribunal Federal (STF) e a Universidade de Brasília (UnB). A NeoLabs AI estende essa linha de pesquisa para o domínio dos crimes f inanceiros, propondo deslocar o trabalho do analista de compliance da coleta fragmentada de dados para a curadoria de evidências previamente organizadas, classificadas e fundamentadas. Em vez de substituir o julgamento humano, o sistema organiza sinais observáveis, materializa cadeias relacionais, ancora classificações em referências normativas explícitas e devolve ao analista uma narrativa estruturada que pode ser revisada, contestada e auditada.
A arquitetura computacional da solução é estruturada em camadas de confiança (“trust layers”), operadas por um ecossistema multi-agente especializado que atua de forma coordenada e assíncrona sob a governança do Agno Framework. Em vez de centralizar a tomada de decisão, a plataforma delega funções estritas a um pipeline de 16 agentes independentes cujo estado de execução é compartilhado via session state centralizado. O processamento é distribuído hierarquicamente: agentes iniciais realizam a validação de identidade e o enriquecimento canônico dos dados; um bloco de sete agentes analíticos paralelos isola sinais preditivos e heurísticos, no qual a análise topológica de redes e grafos opera como um pilar especializado de detecção relacional, uma esteira de motores determinísticos consolida os scores de risco e, por fim, agentes explicativos baseados em LLM geram a fundamentação jurídica e normativa das evidências. Essa segregação funcional garante que os modelos analíticos gerem apenas evidências matemáticas estruturadas, deixando as narrativas e enquadramentos regulatórios sob a estrita tutela de agentes cognitivos controlados, o que mitiga o risco de alucinações algorítmicas e blinda a integridade da tomada de decisão humana.
O grande motor de alimentação desse ecossistema é a sua abrangência dominante de bases públicas, consolidando um repositório massivo que integrará um total de 63 bases de dados. Essa estratégia de dados não se limita a espelhar repositórios estáticos comuns de mercado; ela executa o cruzamento multifatorial de dados cadastrais essenciais e cadastros de sanções administrativas administrados pela CGU (como CEIS, CNEP e CEPIM). O pipeline de dados foi desenhado para atualizar as informações continuamente em produção, garantindo que a base de conhecimento reflita com precisão o status corporativo e sancionatório das entidades consultadas.
Como diferencial de enriquecimento, a plataforma integra bases altamente diferenciadas e historicamente complexas de serem estruturadas. Entre elas destacam-se os atos administrativos e decretos publicados no Diário Oficial da União (DOU via INLABS) e do Distrito Federal (DODF), o cadastro completo de Quadro de Sócios e Administradores (QSA da Receita Federal), e umrobusto ecossistema analítico capaz de indexar as minúcias de mais de 300 milhões de processos judicial distribuídos nas instâncias do país através do DataJud. Essa granularidade permite rastrear desde vínculos empregatícios secundários até o envolvimento indireto de contrapartes em litígios de corrupção ou improbidade administrativa.
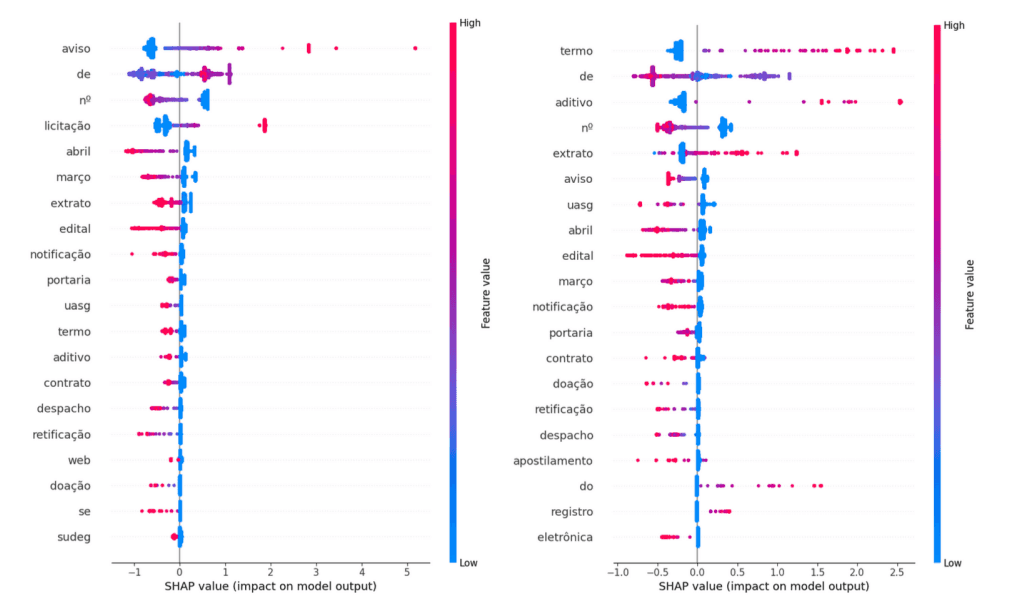
Figura 1: Gráficos de valores SHAP para cada feature encontrada no agrupamento nãosupervisionado do Diário Oficial da União. A escala de cores indica, conforme legenda lateral, a presença de cada token para cada artigo e, em sua distribuição espacial, a sua influência relativa às outras features em determinar categoricamente cada característica do artigo DOU.

Figura 2: Para cada uma das categorias de relações encontradas no Diário Oficial da União, é necessário indicar a precisão que os modelos possuem em encontrá-la em relação às outras em um plano cartesiano. Essa figura indica a precisão de cada modelo em uma Matriz de Confusão.
Diferencial de Mercado
No cenário atual, as soluções globais e domésticas de compliance concentram-se em duas abordagens tradicionais: o screening puramente estático de listas ou o monitoramento transacional voltado ao varejo (smurfing e estruturação), deixando uma lacuna severa na análise profunda de estruturas societárias. A NeoLabs AI diferencia-se ao focar na raiz do risco corporativo de atacado: a engenharia societária utilizada para ocultar Pessoas Expostas Politicamente (PEPs) indiretas e conexões com jurisdições offshore não cooperativas. O produto combina o poder de processamento geométrico sobre bases locais com uma esteira automatizada de classificação jurídica inteiramente alinhada às exigências do Banco Central do Brasil.
O pilar central dessa diferenciação reside no foco absoluto em auditoria e explicabilidade, materializado através do conceito de explicabilidade dupla (dual explainability). Ao avaliar uma contraparte, o sistema não emite apenas um score de risco opaco do tipo "caixa-preta"; ele fornece uma decomposição matemática detalhada via valores SHAP (Shapley Additive exPlanations), isolando o impacto exato de cada variável (estrutural, sancionatória ou reputacional) no cálculo do score final. Paralelamente, esse resultado estatístico é acompanhado por uma fundamentação jurídica explícita redigida por uma IA generativa especializada, que cita diretamente os artigos da Lei n. 9.613, os normativos da Circular BACEN 3.978 e as tipologias de risco consolidadas pelo COAF. A robustez desse modelo de explicabilidade é garantida pelas camadas de confiança da arquitetura multi-agente. O agente responsável pela redação jurídica opera sob regras estritas de guardrails, cruzando as evidências extraídas do grafo com uma base de conhecimento jurídica previamente curada. Caso o modelo identifique uma situação de ambiguidade na resolução de uma entidade ou registre baixa confiança na aplicação de uma tipologia do COAF, o sistema ativa automaticamente um mecanismo de fallback, rotulando o caso para revisão humana obrigatória. Isso impede o vazamento de falsos positivos ou classificações errôneas para o artefato final.
O produto final entregue ao analista de compliance é um relatório COAF automatizado e auditável em formato PDF, que serve como prova pericial definitiva de due diligence para auditorias internas e inspeções regulatórias. Cada relatório gerado é assinado digitalmente e atrelado a um registro de audit log imutável, contendo o timestamp exato da operação, a identificação do usuário e o hash criptográfico de todas as evidências coletadas nas fontes públicas. Esse nível de segurança jurídica reduz o tempo médio de análise das instituições em pelo menos 60%, blindando a liderança corporativa (como o MLRO e o Head de Compliance) contra penalidades administrativas por falha de monitoramento.
Escolha de Métodos
A inexistência de uma solução algorítmica única para muitos dos os problemas de classificação e detecção é um princípio metodológico bem estabelecido na literatura de aprendizado de máquina - o teorema "no free lunch" (WOLPERT, 1996) demonstra que nenhuma técnica isolada resolve sozinha problemas complexos em domínios regulados. Por essa razão, a coordenação técnica da NeoLabs AI adota uma abordagem iterativa e empírica, estruturando ciclos curtos de experimentação multidisciplinar para caracterizar estatisticamente o problema antes da seleção final de modelos. Essa postura permite mitigar a dívida técnica e construir uma trilha documental sólida que sustenta a defensabilidade futura das decisões metodológicas perante auditorias.
No estágio de análise exploratória e pré-processamento de dados, a plataforma utiliza técnicas de redução de dimensionalidade para tornar o espaço hiperdimensional de características tratável por inspeção humana. Algoritmos como PCA são aplicados para projetar centenas de variáveis complexas em espaços multidimensionais. Esse procedimento serve para verificar visualmente se a separação estatística das classes anômalas coincide com a intuição técnica e jurídica do problema de PLD/CFT, garantindo que as variáveis consideradas matematicamente relevantes pelo sistema possuam materialidade prática para os especialistas humanos. Para os dados textuais não estruturados originários de diários oficiais, técnicas clássicas de processamento de linguagem natural (NLP), tais como stemming, lematização, n-grams e TF-IDF, são combinadas com representações distribuídas e embeddings contextuais derivados de modelos transformer pré-treinados em corpus jurídico brasileiro.
A heurística de desenvolvimento de modelos da plataforma segue uma progressão rigorosa do simples ao sofisticado. O pipeline inicia obrigatoriamente com o estabelecimento de um baseline forte por meio de modelos lineares e interpretáveis (como regressão logística e SVM). À medida que a complexidade do cenário exige maior poder de generalização, o sistema migra para classificadores tabulares avançados (XGBoost) e detectores não supervisionados de anomalias transacionais (Isolation Forest). Arquiteturas de Deep Learning baseadas em Redes Neurais de Grafos Heterogêneas (HGNNs) são reservadas estritamente para o mapeamento de padrões relacionais profundos e ocultação patrimonial multi-camadas, onde os ganhos de performance justificam o custo computacional agregado.
Sinal Observável como Unidade Metodológica
Um conceito metodológico central na arquitetura da NeoLabs AI é o de sinal observável: a unidade atômica de evidência mensurável que sustenta qualquer classificação de risco na plataforma. Cada alerta gerado pelo sistema é rigorosamente decomposto em uma cadeia de sinais observáveis individualmente verificáveis, possuindo origem documental rastreável, critério objetivo de medição, definição de janela temporal e uma tipologia regulatória explicitamente associada. Sem o preenchimento dos dados mínimos obrigatórios estipulados para o cálculo de cada sinal, a hipótese analítica permanece inconclusiva, o que impede a geração de falsos positivos e blinda o sistema contra alucinações.
A título de ilustração prática, considere-se a técnica de fracionamento ou estruturação transacional (smurfing). A definição técnica consiste na divisão deliberada de valores financeiros em quantias menores para burlar os limites de comunicação obrigatória automática aos órgãos de controle (como o limiar de R$ 10.000,00 para operações em espécie). O sinal observável mapeado para essa infração mede de forma estritamente matemática o indicador: depósito de N valores em espécie inferiores a R$ 10.000,00 dentro de uma janela temporal móvel de 24 a 72 horas, totalizando um montante acumulado superior a R$ 30.000,00. A ancoragem normativa do sinal é vinculada à Resolução BCB nº 50/2020, art. 37, inciso I, correlacionada diretamente à Tabela 3.1 do Guia de Tipologias do COAF ("Depósitos fragmentados em nome de terceiros"), acionando um prazo regulatório de comunicação de um dia útil.
Esse mesmo princípio de decomposição pericial e parametrização temporal aplica-se a todas as demais tipologias cobertas pelos agentes analíticos da plataforma:
Uso de Interpostos e "Laranjas": Identificado quando a movimentação de crédito ou débito é superior a 10 vezes a renda declarada com um giro de recursos superior a 95% do saldo, sob o amparo da Resolução BCB nº 50/2020 (art. 37), exigindo prazo de comunicação de três dias úteis.
Exposição a Jurisdições Opacas (Offshores): Rastreamento de transferências internacionais (TED/SWIFT) superiores a USD 10.000,00 direcionadas a paraísos fiscais constantes nas listas restritivas do COAF, com prazo de reporte de um dia útil.
Subfaturamento Imobiliário: Sinais que detectam divergências superiores a 30% entre o valor formalizado em contrato e o laudo de avaliação de mercado do ativo.
Empresas de Fachada: Sinalização baseada em inconsistência fiscal e operacional, acionada quando o faturamento declarado é superior a 5 vezes a média do respectivo setor (CNAE) concomitante com o registro de zero funcionários cadastrados.
Essa granularidade assegura que cada julgamento algorítmico possa ser auditado de forma isolada por revisores humanos, uma vez que o pipeline de dados rejeita sumariamente qualquer alerta cuja cadeia de sinais observáveis careça de lastro ou evidência documental verificável nas bases de dados públicas.
Features Previstas em Roadmap
O desenvolvimento tecnológico da plataforma foi planejado em fases incrementais estritas para garantir maturidade e estabilidade computacional. Na fase inicial (v1), o sistema consolida a ingestão das fontes primárias da Receita Federal e cadastros de sanções da CGU, estabelecendo o algoritmo básico de identificação de UBO com regras de corte de participação direta ou indireta. O roadmap de curto e médio prazo (Fase de Consolidação) prevê a expansão da cobertura de dados para englobar a totalidade das 63 bases públicas, incorporando de forma nativa os dados do Portal da Transparência, da Plataforma Nacional de Contratações Públicas (PNCP) e do Transferegov para capturar o fluxo de recursos federais e contratos públicos.
No coração analítico do roadmap está a substituição dos algoritmos tradicionais baseados em regras por uma Rede Neural de Grafos Heterogênea (HGNN) aplicada sobre o grafo de contrapartes completo. Essa arquitetura de aprendizado profundo será treinada utilizando como verdade fundamental (ground truth) os históricos de casos públicos e documentados de lavagem de dinheiro no Brasil, capacitando os agentes de IA a detectar anomalias estruturais altamente complexas, como ciclos de auto-propriedade, pulverização societária deliberada e triangulações fraudulentas de capital. O modelo processará de forma nativa a camada de mais de 300 milhões de processos judiciais e os diários oficiais para derivar perfis longitudinais de risco reputacional. Outra funcionalidade de alto valor planejada para as próximas iterações é o mecanismo de comparação temporal e snapshotting. Essa funcionalidade permitirá que os analistas de compliance congelem o estado de um grafo societário em uma determinada data e o comparem analiticamente com a configuração atual da empresa. O sistema emitirá alertas automáticos sempre que houver uma alteração societária relevante na carteira monitorada, como a entrada repentina de um novo sócio com perfil de risco elevado, a alteração abrupta de CNAE ou a desconexão inexplicável de um nó na cadeia de controle.
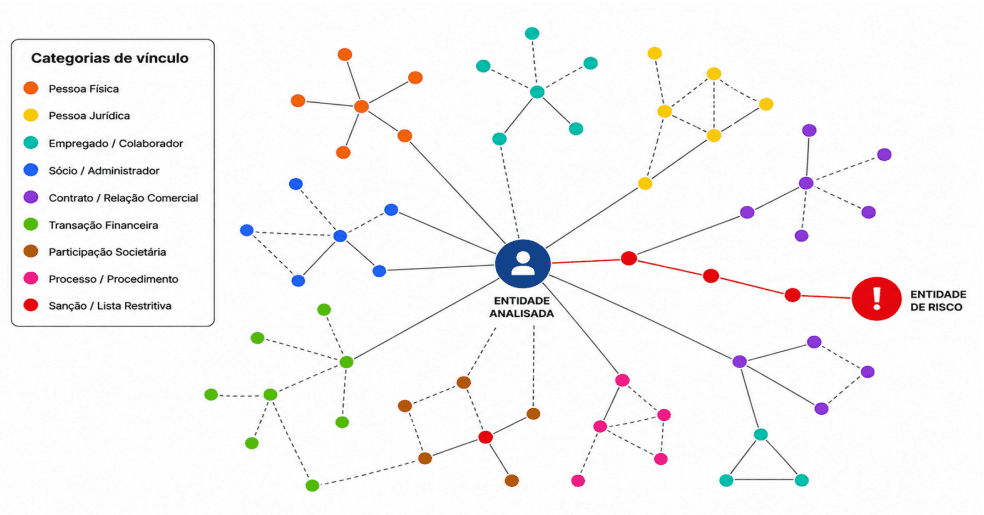
Figura 3: Representação conceitual da análise de risco em grafo heterogêneo.
Finalmente, visando a disponibilização corporativa em larga escala e a governança regulatória, o roadmap projeta a entrega de um módulo avançado de exportação em lotes formatados para a supervisão do BACEN. Essa ferramenta estruturará as evidências e os logs de decisão multiagente exatamente nos padrões exigidos pelos fiscais do órgão regulador durante os ciclos oficiais de auditoria.
Estrutura Técnica e Arquitetura Tecnológica
A infraestrutura tecnológica da plataforma NeoLabs AI é implementada através de uma arquitetura monolítica modular de alta performance em Python, combinando o ecossistema FastAPI para exposição de APIs assíncronas e Celery sob RabbitMQ e Redis para a orquestração distributiva de tarefas em segundo plano. O núcleo cognitivo do sistema baseia-se no Agno Framework, utilizando o mecanismo de Agno Workflow estruturado em passos (steps) rígidos e isolados, os quais compartilham o estado operacional por meio de um barramento centralizado de session state. A segregação funcional estabelecida pelo framework dita que os agentes analíticos, responsáveis pela detecção atomizada de sinais observáveis através de modelos estatísticos (como Isolation Forest e XGBoost) e heurísticas determinísticas, operem de forma totalmente isolada dos consolidadores matemáticos de risco e dos agentes explicativos baseados em IA generativa. Essa separação arquitetural garante que nenhum agente possua autoridade única sobre o risk level final, blindando o pipeline contra vieses ou desvios de lógica computacional.
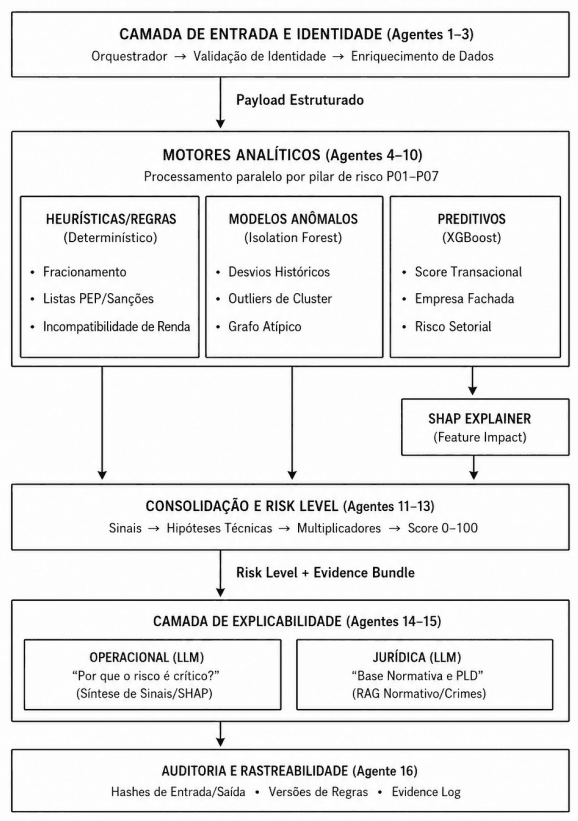
Figura 4: Arquitetura do pipeline multiagente para análise de risco em PLD/CFT, organizado em camadas de entrada, motores analíticos, consolidação do risk level, explicabilidade e auditoria. O fluxo evidencia a separação entre validação de dados, modelos determinísticos, anômalos e preditivos, geração de evidências e rastreabilidade do processo decisório.
O processo de correlação de entidades e enriquecimento de dados apoia-se em um modelo relacional mapeado via SQLAlchemy assíncrono sobre PostgreSQL, segmentado nos schemas aml e canonical. O schema canonical unifica e normaliza os dados operacionais em núcleos estruturados de tabelas: core, corporate, financial, legal, political, publications, assets, sanctions e watchlists. Uma das características mais singulares desse ecossistema é o subsistema de reconhecimento e correlação de entidades via Diário Oficial da União (DOU via INLABS) e do Distrito Federal (DODF), o qual processa minúcias de publicações textuais oficiais em tempo real. Utilizando pipelines customizados de mineração de texto e Reconhecimento de Entidades Nomeadas (NER), o sistema extrai atos administrativos de nomeação, exoneração, sanções federais e licitações inidôneas, vinculando CPFs e CNPJs citados indiretamente aos cadastros estruturados da Receita Federal (CNPJ, QSA e CNAE) e de Tribunais Superiores, resolvendo homônimos e ambiguidades por meio de algoritmos avançados de record linkage utilizando modelos de 8-26 bilhões de parâmetros.
A avaliação de vínculos profundos e ocultação patrimonial é viabilizada por uma camada avançada de processamento topológico baseada no banco de dados gráfico distribuído Neo4j. A plataforma projeta as informações do modelo canônico em uma rede semântica composta pelas abstrações GraphNode e GraphEdge, governada por esquemas e restrições estritas de relacionamento operadas via migrações estruturadas em Cypher. Este ecossistema de grafos mapeia conexões complexas e calcula distâncias geodésicas e caminhos críticos entre os nós para reconhecer relações multi-camadas de risco, identificando automaticamente anomalias relacionais como redes de laranjas, procuradores compartilhados, empresas de fachada sem atividade operacional aparente compartilhando endereços físicos, e o fluxo indireto para Pessoas Expostas Politicamente (PEPs) registradas nos portais de transparência, candidaturas ou doações eleitorais do TSE. Os agentes analíticos de grafo traduzem essa topologia em variáveis tabulares (graph feature engineering), permitindo que regras determinísticas e modelos anômalos isolem comportamentos como o de contas-funil ou de passagem, nas quais múltiplos créditos pulverizados convergem para um beneficiário comum seguido de dispersão rápida.
A automação completa da auditoria e a explicabilidade algorítmica constituem o pilar de governança regulatória e transparência da solução, operacionalizado de forma transversal ao ciclo de execução do workflow. A cada passo analítico concluído, a camada de auditoria intercepta as entradas, as configurações de parâmetros, as regras ativas de suficiência, os multiplicadores aplicados e as saídas estruturadas, persistindo de forma permanente e imutável esses metadados na tabela física de rastreamento aml.analysis_step_runs, registrando o hash criptográfico de cada evidência e congelando um snapshot dos dados públicos consultados. Essa trilha pericial coleta os hashes criptográficos dos documentos originais e armazena os instantâneos (snapshots) exatos das evidências coletadas nas fontes públicas, incluindo dados processuais do DataJud (CNJ), restrições do SCR/CCS do BACEN, cadastros punitivos (como a lista suja do MTE e embargos do IBAMA) e tipologias do COAF. Desse modo, o histórico decisório do sistema multi-agente pode ser integralmente reproduzido e auditado a qualquer momento, garantindo o cumprimento estrito das diretrizes de supervisão digital exigidas pelo Open Finance e pela agenda de conformidade do Banco Central do Brasil.
Finalmente, a conversão dessas métricas e auditorias em conhecimento inteligível é executada na etapa final do fluxo pelos agentes de Explicação Operacional e Explicação Jurídica/Normativa. O motor de inteligência explicativa (XAI) extrai as contribuições locais calculadas pelo modelo SHAP a partir dos vetores de características dos modelos preditivos e as empacota em um payload altamente estruturado. Esse conteúdo técnico serve como entrada para grandes modelos de linguagem (LLMs) configurados sob estritos critérios de enquadramento normativo e arquitetura de Geração Aumentada de Recuperação (RAG) controlada. Os agentes de IA decodificam os scores estatísticos e as tipologias de grafos em textos fundamentados na legislação brasileira de PLD, correlacionando os sinais de forma clara e emitindo relatórios COAF automatizados, sem que a inteligência generativa possua qualquer permissão para alterar pontuações, inventar dados ou inserir novas evidências à revelia do que foi rigorosamente processado e documentado nas camadas de confiança do sistema.

Figura 5: Consolidação visual do nível de risco agregado da contraparte analisada, calculado a partir dos pilares analíticos representados pelos eixos P01–P07. O gráfico radar apresenta a distribuição dos scores individuais por dimensão de risco, permitindo identificar quais pilares mais contribuíram para a composição do resultado final. À direita, o valor consolidado do risk level sintetiza a avaliação global da entidade em uma escala de 0 a 100, servindo como indicador executivo para priorização de análise, revisão humana e eventual aprofundamento investigativo.
Referências Bibliográficas
1. Documentos Institucionais e Especificações Técnicas (NeoLabsAI)
BANDINELLI, Diéferson. NeoLabsAI counterparty intelligence: especificação de requisitos de produto (PRD). Versão 0.3. [S. l.: s. n.], 2026.
NEOLABSAI. Agentes do Sistema Multiagente AML: documentação de arquitetura de software e workflow. [S. l.: s. n.], 2026.
NEOLABSAI. Documento Guia — Sinal Observável: manual metodológico de PLD/CFT. [S. l.: s. n.], 2026.
NEOLABSAI. Documento Guia — Técnica: matriz de modus operandi de lavagem de dinheiro. [S. l.: s. n.], 2026.
2. Legislação, Normatização Regulatória e Relatórios Governamentais / Institucionais
BANCO CENTRAL DO BRASIL. Circular nº 3.978, de 23 de janeiro de 2020. Dispõe sobre a política, os procedimentos e os controles internos a serem adotados pelas instituições autorizadas a funcionar pelo Banco Central do Brasil, visando à prevenção da utilização do sistema financeiro para a prática dos crimes de "lavagem" ou ocultação de bens, direitos e valores. Brasília, DF: BACEN, 2020.
BANCO CENTRAL DO BRASIL. Resolução BCB nº 50, de 16 de dezembro de 2020. Dispõe sobre a atividade de registro de comunicações e os procedimentos de remessa de informações ao COAF. Brasília, DF: BACEN, 2020.
BANCO CENTRAL DO BRASIL. Resolução BCB nº 519, de 6 de fevereiro de 2025. Dispõe sobre as diretrizes de monitoramento e compliance de ativos virtuais no ecossistema financeiro nacional. Brasília, DF: BACEN, 2025.
BRASIL. Lei nº 9.613, de 3 de março de 1998. Dispõe sobre os crimes de "lavagem" ou ocultação de bens, direitos e valores; a prevenção da utilização do sistema financeiro para os ilícitos previstos nesta Lei; cria o Conselho de Controle de Atividades Financeiras - COAF, e dá outras providências. Brasília, DF: Presidência da República, 1998.
BRASIL. Lei nº 13.709, de 14 de agosto de 2018. Lei Geral de Proteção de Dados Pessoais (LGPD). Brasília, DF: Presidência da República, 2018.
CFA INSTITUTE. Explainable AI in Finance: Addressing the Needs of Diverse Stakeholders. [S. l.]: CFA Institute Research and Policy Center, 2025.
CONSELHO DE CONTROLE DE ATIVIDADES FINANCEIRAS (COAF). Tipologias de lavagem de dinheiro: relatórios públicos e comunicações compulsórias. Brasília, DF: COAF, 2024.
CONSELHO NACIONAL DE JUSTIÇA (CNJ). Resolução nº 331, de 20 de agosto de 2020. Institui a Base Nacional de Dados do Poder Judiciário (DataJud) como fonte primária de metadados processuais estatísticos do país. Brasília, DF: CNJ, 2020.
FATF/GAFI. Money Laundering National Risk Assessment Guidance. Paris: FATF, 2024.
GARTNER. Market Guide for AML Transaction Monitoring Solutions. [S. l.]: Gartner, 2025.
UNODC. Money-Laundering and Globalization. Vienna: ONU, 2023.
3. Literatura Científica e Algorítmica (Modelos Base, NLP e GNNs)
CHEN, Tianqi; GUESTRIN, Carlos. XGBoost: A scalable tree boosting system. In: ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING, 22., 2016, San Francisco. Proceedings... New York: ACM, 2016. p. 785-794.
CHENG, D.; ZOU, Y.; XIANG, S.; JIANG, C. Graph Neural Networks for Financial Fraud Detection: A Review. arXiv preprint arXiv:2411.05815, 2024.
DI GENNARO, M.; PANEBIANCO, F.; PIANTA, M.; ZANERO, S.; CARMINATI, M. Amatriciana: Exploiting Temporal GNNs for Robust and Efficient Money Laundering Detection. arXiv preprint arXiv:2506.00654, 2025.
DO, C. B.; NG, A. Y. Transfer Learning for Text Classification. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS (NeurIPS), 18., 2005. Proceedings... v. 18, p. 299, 2005.
EXPLAINABLE and fair anti-money laundering models using a reproducible SHAP framework for financial institutions. Discover Artificial Intelligence, Springer, v. 6, 2026.
FERNANDES, R. V. C.; MENDES, D. B.; CARVALHO, G. H. T. A.; FERREIRA, H. H. The VICTOR Project: Applying artificial intelligence to Brazil's Supreme Federal Court. In: Research Handbook on Big Data Law. Cheltenham: Edward Elgar, 2021. p. 304–317.
FINDING money launderers using heterogeneous graph neural networks. Expert Systems with Applications, v. 260, 2025.
HINTON, G. Reducing the Dimensionality of Data with Neural Networks. Science, v. 313, n. 5786, p. 504-507, 2006.
LIU, Fei Tony; TING, Kai Ming; ZHOU, Zhi-Hua. Isolation forest. In: IEEE INTERNATIONAL CONFERENCE ON DATA MINING (ICDM), 8., 2008, Pisa. Proceedings... Piscataway: IEEE, 2008. p. 413-422.
LUNDBERG, Scott M.; LEE, Su-In. A unified approach to interpreting model predictions. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS (NeurIPS), 30., 2017, Long Beach. Proceedings... Long Beach: NeurIPS, 2017. p. 4765-4774.
LUZ, F. et al. LeNER-Br: A Dataset for Named Entity Recognition in Brazilian Legal Text. In: INTERNATIONAL CONFERENCE ON COMPUTATIONAL PROCESSING OF THE PORTUGUESE LANGUAGE (PROPOR), 13., 2018, Canela. Proceedings... Berlin: Springer, 2018.
MIKOLOV, T. et al. Distributed Representations of Words and Phrases and Their Compositionality. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS (NeurIPS), 26., 2013, Lake Tahoe. Proceedings... Lake Tahoe: NeurIPS, 2013.
NUNES, R. O.; BALREIRA, D. G.; SPRITZER, A. S.; FREITAS, C. M. D. S. A Named Entity Recognition Approach for Portuguese Legislative Texts Using Self-Learning. In: INTERNATIONAL CONFERENCE ON COMPUTATIONAL PROCESSING OF THE PORTUGUESE LANGUAGE (PROPOR), 16., 2024. Proceedings... 2024.
PENNINGTON, J.; SOCHER, R.; MANNING, C. GloVe: Global Vectors for Word Representation. In: CONFERENCE ON EMPIRICAL METHODS IN NATURAL LANGUAGE PROCESSING (EMNLP), 2014, Doha. Proceedings... Doha: ACL, 2014. p. 1532-1543.
RIBEIRO, M. T.; SINGH, S.; GUESTRIN, C. Why Should I Trust You?: Explaining the Predictions of Any Classifier. In: ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING, 22., 2016, San Francisco. Proceedings... New York: ACM, 2016. p. 1135-1144.
VAN DER MAATEN, L.; HINTON, G. Visualizing Data Using t-SNE. Journal of Machine Learning Research, v. 9, p. 2579-2605, 2008.
WOLPERT, D. H. The Lack of A Priori Distinctions Between Learning Algorithms. Neural Computation, v. 8, n. 7, p. 1341-1390, 1996.
ZHONG, Erheng et al. Graph neural networks for heterogeneous networks. In: ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING, 18., 2012, Beijing. Proceedings... New York: ACM, 2012. p. 913-921.
//
Latest Blogs
