
Ricardo V. C. Fernandes, Sydnei M. Gomes, Marcos V. Mantovani, Stephannie L. A. P. Chiang Ozawa, Daniel E. Gomes, Guilherme Sardinha
The NeoLabs AI platform arises from a clearly defined technical and regulatory premise: Brazil's AntiMoney Laundering and Countering the Financing of Terrorism (AML/CFT) framework...
NeoLabs AI Platform for Regulatory Intelligence and Explainability
Ricardo V. C. Fernandes
Postdoctoral researcher in Legal Artificial Intelligence at CODEX - The Stanford Center for Legal Informatics. Creator and coordinator of the VICTOR Project, the AI system of the Brazilian Supreme Federal Court. Ph.D. in Law from the University of Brasilia (UnB).
Strategic AI Researcher at NeoLabs AI
Sydnei M. Gomes
Specialist in Artificial Intelligence, Software Engineering, and Infrastructure. B.A. in Information Technology Management from the Catholic University of Brasilia.
AI Engineering Director at NeoLabs AI.
Marcos V. Mantovani
Specialist in Artificial Intelligence, Multi-Agent Systems, and Software Engineering. Undergraduate student in Systems Analysis and Development at UNINTER. Technical Lead for Artificial Intelligence at NeoLabs AI.
Stephannie L. A. P. Chiang Ozawa
Specialist in data engineering, scalable pipelines, and Big Data architectures. B.S. in Computer Engineering from the University of Brasilia.
Senior Pipeline Engineer at NeoLabs AI.
Daniel E. Gomes
MBA specialist in Big Data structures. B.A. in Law from the University Center of Brasilia.
Technical AI Researcher at NeoLabs AI.
Guilherme Sardinha
Director of Legal Investments Operations at Grupo DNR.
Specialist in AI Risk/Governance
May 27, 2026
Introduction
The NeoLabsAI platform arises from a well-defined technical and regulatory observation: the Brazilian framework for Anti-Money Laundering and Countering the Financing of Terrorism (AML/CFT) — supported by Law No. 9,613/1998, BACEN Circular No. 3,978/2020, BACEN Circular Letter No. 4,001/2020, and the typologies published by the Council for Financial Activities Control (COAF) — requires financial institutions to possess three simultaneous capabilities that rarely coexist within the same platform: identifying suspicious signals at scale, organizing technical and legal foundations to support human decision-making, and documenting the evidentiary trail in an auditable manner. Specifically directed at the investment banking and wealth management market, the system was designed to solve the critical problem of counterparty opacity, responding in near-real time to complex questions regarding the identity of ultimate beneficial owners (UBO) and the regulatory risks associated with interposed holding companies or concealed corporate structures.
The development of the platform reflects the academic and institutional tradition of its engineering team, which carries a direct legacy from frontier research in legal artificial intelligence — including Project VICTOR, the first AI system applied to a Supreme Court in the world, developed in partnership between the Brazilian Supreme Federal Court (STF) and the University of Brasília (UnB). NeoLabs AI extends this line of research into the domain of financial crimes, proposing to shift the work of the compliance analyst from fragmented data collection to the curation of previously organized, contextualized, and substantiated evidence. Rather than replacing human judgment, the system organizes observable signals, materializes relational chains, anchors alerts and risk hypotheses in explicit regulatory references, and returns to the analyst a structured narrative that can be reviewed, challenged, and audited.
The computational architecture of the solution is structured in trust layers, operated by a specialized multi-agent ecosystem that acts in a coordinated and asynchronous manner under the governance of the Agno Framework. Rather than centralizing decision-making, the platform delegates strict functions to a pipeline of 16 independent agents whose execution state is shared through centralized session state. Processing is distributed hierarchically: initial agents perform identity validation and canonical data enrichment; a block of seven parallel analytical agents isolates predictive and heuristic signals, in which topological network and graph analysis operates as a specialized pillar of relational detection; a chain of deterministic engines consolidates risk scores; and, finally, LLM-based explanatory agents generate the legal and regulatory substantiation of the evidence. This functional segregation ensures that analytical models generate only structured mathematical evidence, leaving narratives and regulatory framing under the strict custody of controlled cognitive agents, thereby mitigating the risk of algorithmic hallucinations and shielding the integrity of human decision-making.
The main data-feeding engine of this ecosystem is its dominant coverage of public databases, consolidating a massive repository that will integrate a total of 63 data sources. This data strategy is not limited to mirroring common static market repositories; it performs multifactorial cross-referencing of essential registration data and administrative sanctions registries managed by the CGU, such as CEIS, CNEP, and CEPIM. The data pipeline was designed to continuously update information in production, ensuring that the knowledge base accurately reflects the corporate and sanctions status of the entities queried.
As an enrichment differentiator, the platform integrates highly differentiated and historically complex databases that are difficult to structure. Among them are administrative acts and decrees published in the Federal Official Gazette (DOU via INLABS) and the Federal District Official Gazette (DODF), the complete registry of Shareholders and Officers (QSA from the Brazilian Federal Revenue Service), and a robust analytical ecosystem capable of indexing the details of more than 300 million judicial proceedings distributed across the country’s court levels through DataJud. This granularity makes it possible to trace anything from secondary employment relationships to the indirect involvement of counterparties in corruption or administrative improbity litigation.
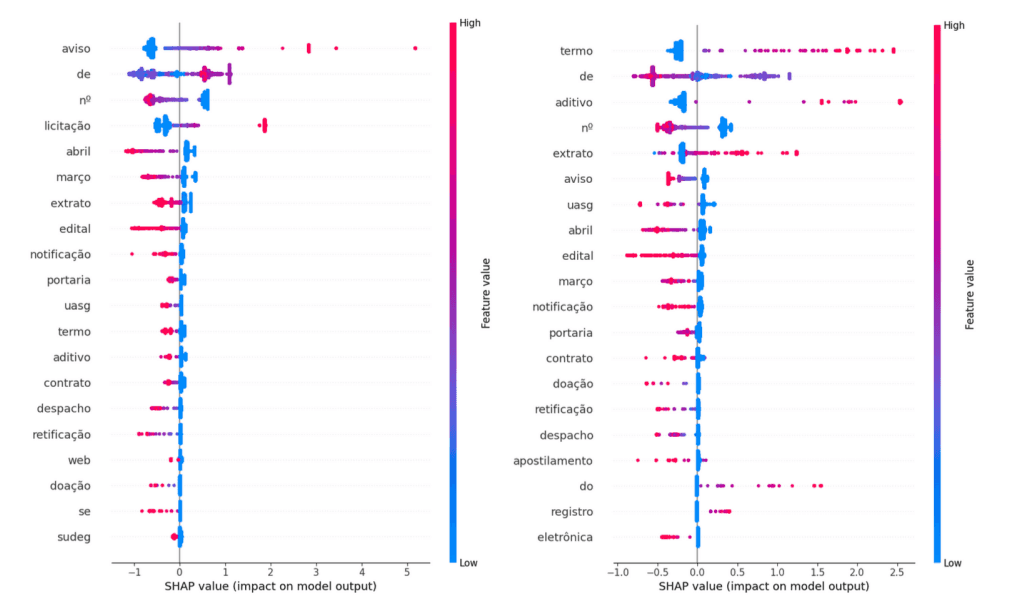
Figure 1: SHAP value plots for each feature found in the unsupervised clustering of the Federal Official Gazette. The color scale indicates, as shown in the side legend, the presence of each token for each article and, through its spatial distribution, its relative influence compared with other features in categorically determining each characteristic of the DOU article.

Figure 2: For each category of relationship identified in the Federal Official Gazette, it is necessary to indicate the precision with which the models identify it relative to the others in a Cartesian plane. This figure reports the precision of each model in a confusion matrix.
Market Differentiation
In the current landscape, global and domestic compliance solutions focus on two traditional approaches: purely static list screening or retail-oriented transactional monitoring, such as smurfing and structuring, leaving a severe gap in the deep analysis of corporate structures. NeoLabs AI differentiates itself by focusing on the root of wholesale corporate risk: corporate engineering used to conceal indirect Politically Exposed Persons (PEPs) and connections with non-cooperative offshore jurisdictions. The product combines the power of geometric processing over local databases with an automated legal classification pipeline fully aligned with the requirements of the Central Bank of Brazil.
The central pillar of this differentiation lies in an absolute focus on auditability and explainability, materialized through the concept of dual explainability. When assessing a counterparty, the system does not merely issue an opaque “black-box” risk score; it provides a detailed mathematical decomposition through SHAP values (Shapley Additive exPlanations), isolating the exact impact of each variable — structural, sanctions-related, or reputational — on the calculation of the final score. In parallel, this statistical result is accompanied by explicit legal reasoning drafted by a specialized generative AI, which directly cites the articles of Law No. 9,613, the provisions of BACEN Circular No. 3,978/2020, and the risk typologies consolidated by COAF. The robustness of this explainability model is guaranteed by the trust layers of the multi-agent architecture. The agent responsible for legal drafting operates under strict guardrail rules, cross-referencing the evidence extracted from the graph with a previously curated legal knowledge base. If the model identifies ambiguity in entity resolution or records low confidence in the application of a COAF typology, the system automatically activates a fallback mechanism, labeling the case for mandatory human review. This prevents false positives or erroneous classifications from leaking into the final artifact.
The final product delivered to the compliance analyst is an auditable AML decision-support report containing alerts, structured evidence, an audit trail, the history of sources consulted, and a draft technical-legal rationale. This report organizes the inputs required for the internal assessment of the obligated institution and may support a potential communication to COAF, should the responsible department decide to characterize the operation or situation as suspicious. Each generated report is linked to an immutable audit log record containing the exact timestamp of the operation, user identification, and the cryptographic hash of all evidence collected from public sources. This level of legal security reduces the average analysis time for institutions and contributes to the demonstrability of internal controls and the reduction of operational risks associated with insufficient documentation, without replacing the regulatory responsibility of the obligated institution.
Choice of Methods
The absence of a single algorithmic solution for many of these classification and detection problems is a well-established methodological principle in the machine learning literature — the “no free lunch” theorem (WOLPERT, 1996) demonstrates that no isolated technique can independently solve complex problems in regulated domains. For this reason, NeoLabs AI’s technical coordination adopts an iterative and empirical approach, structuring short cycles of multidisciplinary experimentation to statistically characterize the problem before the final selection of models. This stance makes it possible to mitigate technical debt and build a solid documentary trail that supports the future defensibility of methodological decisions before audits.
At the exploratory analysis and data preprocessing stage, the platform uses dimensionality reduction techniques to make the hyperdimensional feature space manageable for human inspection. Algorithms such as PCA are applied to project hundreds of complex variables into multidimensional spaces. This procedure is used to visually verify whether the statistical separation of anomalous classes coincides with the technical and legal intuition of the AML/CFT problem, ensuring that the variables considered mathematically relevant by the system have practical materiality for human specialists. For unstructured textual data originating from official gazettes, classical natural language processing (NLP) techniques, such as stemming, lemmatization, n-grams, and TF-IDF, are combined with distributed representations and contextual embeddings derived from transformer models pre-trained on Brazilian legal corpora.
The platform’s model development heuristic follows a rigorous progression from simple to sophisticated. The pipeline necessarily begins with the establishment of a strong baseline through linear and interpretable models, such as logistic regression and SVM. As the complexity of the scenario demands greater generalization power, the system migrates to advanced tabular classifiers, such as XGBoost, and unsupervised detectors of transactional anomalies, such as Isolation Forest. Deep Learning architectures based on Heterogeneous Graph Neural Networks (HGNNs) are reserved strictly for the mapping of deep relational patterns and multilayer asset concealment, where performance gains justify the additional computational cost.
Observable Signal as a Methodological Unit
A central methodological concept in the NeoLabs AI architecture is the observable signal: the atomic unit of measurable evidence that supports any risk classification within the platform. Each alert generated by the system is rigorously decomposed into a chain of individually verifiable observable signals, with traceable documentary origin, an objective measurement criterion, definition of a time window, and an explicitly associated regulatory typology. Without the minimum mandatory data stipulated for the calculation of each signal, the analytical hypothesis remains inconclusive, preventing the generation of false positives and shielding the system against hallucinations.
As a practical illustration, consider the technique of transactional fragmentation or structuring, also known as smurfing. The technical definition consists of the deliberate division of financial amounts into smaller sums, within a short time interval, with the objective of concealing the total amount moved or avoiding the application of controls, enhanced records, and regulatory communications applicable to cash transactions. The observable signal mapped to this hypothesis measures, as an internal operational risk parameter, the occurrence of multiple cash deposits, contributions, or withdrawals individually below the thresholds defined by the institution’s monitoring policy, within a moving time window of 24 to 72 hours, when the accumulated amount appears incompatible with the client’s economic profile or declared activity. These parameters are not treated as autonomous regulatory thresholds for automatic reporting, but as internal analytical selection criteria for identifying possible structuring.
The normative anchoring of the signal relates to the monitoring, selection, and analysis procedures provided for in BACEN Circular No. 3,978/2020, as well as to the illustrative situations in BACEN Circular Letter No. 4,001/2020 concerning the fragmentation of deposits, withdrawals, and other cash transfer instruments. Any communication to COAF must observe the applicable regulatory flow: selection and analysis of the operation, formalization in a dossier, and communication by the business day following the decision to report, when the situation is characterized as suspicious.
This same principle of expert decomposition and temporal parameterization applies to all other typologies covered by the platform’s analytical agents:
Use of Interposed Parties and “Straw Men”: Identified when credit or debit movements are incompatible with declared income, assets, or economic and financial capacity, especially when there are indications of acting on behalf of third parties, difficulty identifying the ultimate beneficial owner, or use of interposed structures.
Exposure to Opaque Jurisdictions (Offshores): Tracking of international transfers directed to higher-risk jurisdictions, countries or territories with strategic AML/CFT deficiencies, or offshore structures incompatible with the economic and operational profile of the counterparty.
Real Estate Underinvoicing: Signals that detect divergences greater than 30% between the value formalized in the contract and the market appraisal report of the asset.
Shell Companies: Signaling based on fiscal and operational inconsistency, triggered when declared revenue is more than five times the average of the respective sector (CNAE) while simultaneously registering zero employees.
This granularity ensures that each algorithmic judgment can be audited in isolation by human reviewers, since the data pipeline summarily rejects any alert whose chain of observable signals lacks support or verifiable documentary evidence in public databases.
Roadmap Features
The technological development of the platform was planned in strict incremental phases to ensure computational maturity and stability. In the initial phase (v1), the system consolidates the ingestion of primary sources from the Brazilian Federal Revenue Service and CGU sanctions registries, establishing the basic UBO identification algorithm with direct or indirect ownership cut-off rules. The short- and medium-term roadmap (Consolidation Phase) provides for the expansion of data coverage to encompass the entirety of the 63 public databases, natively incorporating data from the Transparency Portal, the National Public Procurement Platform (PNCP), and Transferegov to capture the flow of federal resources and public contracts.
At the analytical core of the roadmap is the replacement of traditional rule-based algorithms with a Heterogeneous Graph Neural Network (HGNN) applied to the complete counterparty graph. This deep learning architecture will be trained using documented public case histories of money laundering in Brazil as ground truth, enabling AI agents to detect highly complex structural anomalies, such as self-ownership cycles, deliberate ownership fragmentation, and fraudulent capital triangulations. The model will natively process the layer of more than 300 million judicial proceedings and official gazettes to derive longitudinal reputational risk profiles. Another high-value functionality planned for the next iterations is the temporal comparison and snapshotting mechanism. This functionality will allow compliance analysts to freeze the state of a corporate graph on a given date and analytically compare it with the company’s current configuration. The system will issue automatic alerts whenever a relevant corporate change occurs in the monitored portfolio, such as the sudden entry of a new partner with a high-risk profile, an abrupt change in CNAE, or the unexplained disconnection of a node in the control chain.
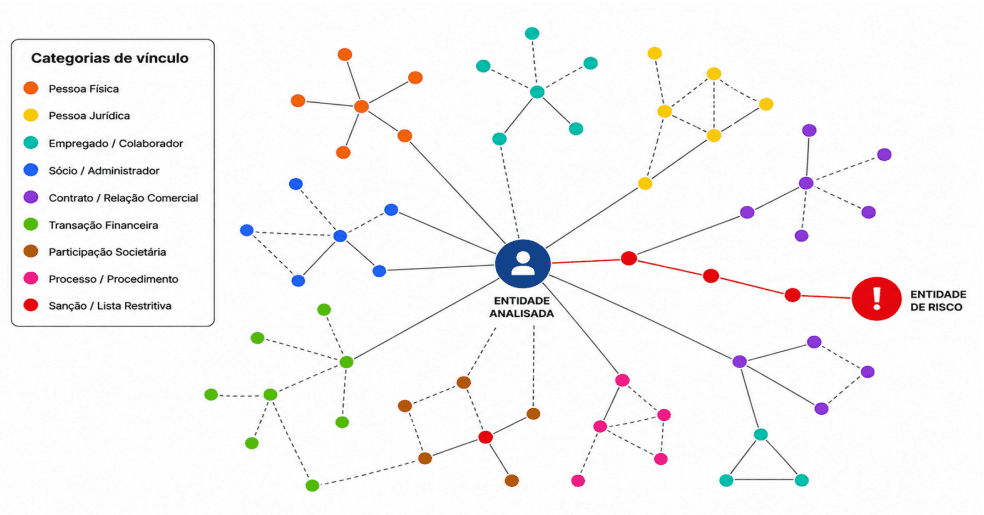
Figure 3: Conceptual representation of risk analysis in a heterogeneous graph.
Finally, aiming at large-scale corporate deployment and regulatory governance, the roadmap projects the delivery of an advanced batch export module formatted for BACEN supervision. This tool will structure the evidence and multi-agent decision logs exactly according to the standards required by the regulator’s inspectors during official audit cycles.
Technical Structure and Technological Architecture
The technological infrastructure of the NeoLabs AI platform is implemented through a high-performance modular monolithic architecture in Python, combining the FastAPI ecosystem for exposing asynchronous APIs and Celery under RabbitMQ and Redis for the distributed orchestration of background tasks. The cognitive core of the system is based on the Agno Framework, using the Agno Workflow mechanism structured into rigid and isolated steps, which share operational state through a centralized session-state bus. The functional segregation established by the framework dictates that analytical agents, responsible for the atomized detection of observable signals through statistical models, such as Isolation Forest and XGBoost, and deterministic heuristics, operate fully isolated from mathematical risk consolidators and generative-AI-based explanatory agents. This architectural separation ensures that no agent has sole authority over the final risk level, shielding the pipeline against biases or deviations in computational logic.
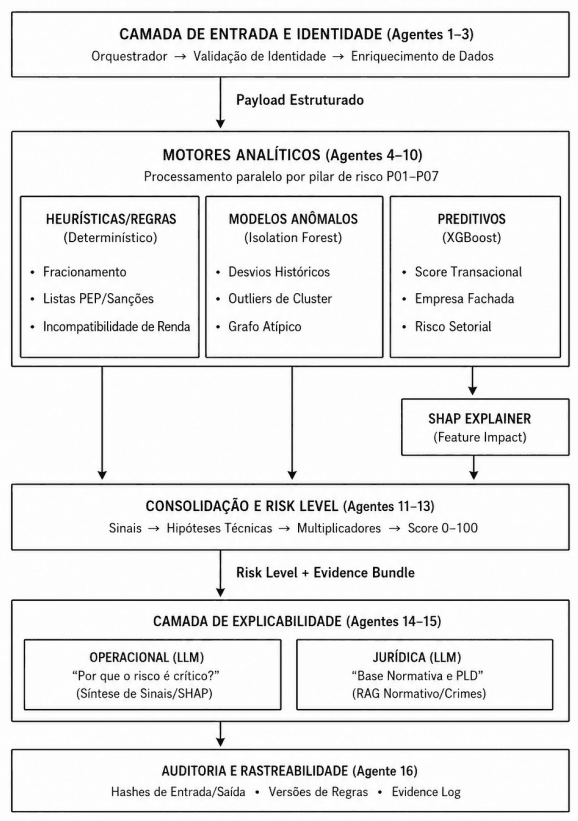
Figure 4: Multi-agent pipeline architecture for AML/CFT risk analysis, organized into layers of input, analytical engines, risk-level consolidation, explainability, and auditing. The flow highlights the separation among data validation, deterministic, anomalous, and predictive models, evidence generation, and decision-process traceability.
The process of entity correlation and data enrichment is supported by a relational model mapped via asynchronous SQLAlchemy over PostgreSQL, segmented into the aml and canonical schemas. The canonical schema unifies and normalizes operational data into structured table cores: core, corporate, financial, legal, political, publications, assets, sanctions, and watchlists. One of the most distinctive characteristics of this ecosystem is the subsystem for entity recognition and correlation through the Federal Official Gazette (DOU via INLABS) and the Federal District Official Gazette (DODF), which processes the details of official textual publications in real time. Using customized text mining and Named Entity Recognition (NER) pipelines, the system extracts administrative acts of appointment, dismissal, federal sanctions, and debarred public bids, linking CPFs and CNPJs cited indirectly to structured registries from the Federal Revenue Service (CNPJ, QSA, and CNAE) and higher courts, resolving homonyms and ambiguities through advanced record linkage algorithms using models with 8 to 26 billion parameters.
The assessment of deep links and asset concealment is enabled by an advanced topological processing layer based on the Neo4j distributed graph database. The platform projects information from the canonical model into a semantic network composed of GraphNode and GraphEdge abstractions, governed by strict relationship schemas and constraints operated through structured Cypher migrations. This graph ecosystem maps complex connections and calculates geodesic distances and critical paths between nodes to recognize multilayer risk relationships, automatically identifying relational anomalies such as straw-man networks, shared attorneys-in-fact, shell companies with no apparent operational activity sharing physical addresses, and indirect flows to Politically Exposed Persons (PEPs) registered in transparency portals, candidacies, or electoral donations from the TSE. Graph analytical agents translate this topology into tabular variables, known as graph feature engineering, allowing deterministic rules and anomalous models to isolate behaviors such as funnel or pass-through accounts, in which multiple fragmented credits converge toward a common beneficiary followed by rapid dispersion.
The complete automation of auditing and algorithmic explainability constitutes the pillar of regulatory governance and transparency of the solution, operationalized transversally across the workflow execution cycle. At each completed analytical step, the audit layer intercepts inputs, parameter configurations, active sufficiency rules, applied multipliers, and structured outputs, permanently and immutably persisting these metadata in the physical tracking table aml.analysis_step_runs, recording the cryptographic hash of each item of evidence and freezing a snapshot of the public data consulted. This expert evidentiary trail collects the cryptographic hashes of the original documents and stores the exact snapshots of the evidence collected from public sources, including DataJud (CNJ) procedural data, punitive registries, and COAF typologies when lawfully made available by the contracting institution or by the data subject, observing the applicable rules of confidentiality, consent, legal basis, and governance. In this way, the decision history of the multi-agent system can be fully reproduced and audited at any time, ensuring strict compliance with the digital supervision guidelines required by Open Finance and by the compliance agenda of the Central Bank of Brazil.
Finally, the conversion of these metrics and audits into intelligible knowledge is performed in the final stage of the flow by the Operational Explanation and Legal/Regulatory Explanation agents. The explanatory intelligence engine (XAI) extracts the local contributions calculated by the SHAP model from the feature vectors of the predictive models and packages them into a highly structured payload. This technical content serves as input for large language models (LLMs) configured under strict normative-framing criteria and a controlled Retrieval-Augmented Generation (RAG) architecture. The AI agents decode statistical scores and graph typologies into texts grounded in Brazilian AML legislation, clearly correlating the signals and producing AML decision-support reports, evidence packages, and draft technical-legal rationales, without the generative intelligence having any permission to alter scores, invent data, insert new evidence, or replace the formal analysis of the obligated institution.

Figure 5: Visual consolidation of the aggregate risk level of the analyzed counterparty, calculated from the analytical pillars represented by axes P01–P07. The radar chart presents the distribution of individual scores by risk dimension, making it possible to identify which pillars contributed most to the composition of the final result. On the right, the consolidated risk-level value summarizes the entity's overall assessment on a scale from 0 to 100, serving as an executive indicator for prioritizing analysis, human review, and potential investigative deepening.
Bibliographic References
1. Institutional Documents and Technical Specifications (NeoLabs AI)
BANDINELLI, Diéferson. NeoLabsAI counterparty intelligence: especificação de requisitos de produto (PRD). Versão 0.3. [S. l.: s. n.], 2026.
NEOLABSAI. Agentes do Sistema Multiagente AML: documentação de arquitetura de software e workflow. [S. l.: s. n.], 2026.
NEOLABSAI. Documento Guia — Sinal Observável: manual metodológico de PLD/CFT. [S. l.: s. n.], 2026.
NEOLABSAI. Documento Guia — Técnica: matriz de modus operandi de lavagem de dinheiro. [S. l.: s. n.], 2026.
2. Legislation, Regulatory Standards, and Governmental/Institutional Reports
BANCO CENTRAL DO BRASIL. Circular nº 3.978, de 23 de janeiro de 2020. Dispõe sobre a política, os procedimentos e os controles internos a serem adotados pelas instituições autorizadas a funcionar pelo Banco Central do Brasil, visando à prevenção da utilização do sistema financeiro para a prática dos crimes de "lavagem" ou ocultação de bens, direitos e valores. Brasília, DF: BACEN, 2020.
BANCO CENTRAL DO BRASIL. Resolução BCB nº 50, de 16 de dezembro de 2020. Dispõe sobre a atividade de registro de comunicações e os procedimentos de remessa de informações ao COAF. Brasília, DF: BACEN, 2020.
BANCO CENTRAL DO BRASIL. Resolução BCB nº 519, de 6 de fevereiro de 2025. Dispõe sobre as diretrizes de monitoramento e compliance de ativos virtuais no ecossistema financeiro nacional. Brasília, DF: BACEN, 2025.
BRASIL. Lei nº 9.613, de 3 de março de 1998. Dispõe sobre os crimes de "lavagem" ou ocultação de bens, direitos e valores; a prevenção da utilização do sistema financeiro para os ilícitos previstos nesta Lei; cria o Conselho de Controle de Atividades Financeiras - COAF, e dá outras providências. Brasília, DF: Presidência da República, 1998.
BRASIL. Lei nº 13.709, de 14 de agosto de 2018. Lei Geral de Proteção de Dados Pessoais (LGPD). Brasília, DF: Presidência da República, 2018.
CFA INSTITUTE. Explainable AI in Finance: Addressing the Needs of Diverse Stakeholders. [S. l.]: CFA Institute Research and Policy Center, 2025.
CONSELHO DE CONTROLE DE ATIVIDADES FINANCEIRAS (COAF). Tipologias de lavagem de dinheiro: relatórios públicos e comunicações compulsórias. Brasília, DF: COAF, 2024.
CONSELHO NACIONAL DE JUSTIÇA (CNJ). Resolução nº 331, de 20 de agosto de 2020. Institui a Base Nacional de Dados do Poder Judiciário (DataJud) como fonte primária de metadados processuais estatísticos do país. Brasília, DF: CNJ, 2020.
FATF/GAFI. Money Laundering National Risk Assessment Guidance. Paris: FATF, 2024.
GARTNER. Market Guide for AML Transaction Monitoring Solutions. [S. l.]: Gartner, 2025.
UNODC. Money-Laundering and Globalization. Vienna: ONU, 2023.
3. Scientific and Algorithmic Literature (Baseline Models, NLP, and GNNs)
CHEN, Tianqi; GUESTRIN, Carlos. XGBoost: A scalable tree boosting system. In: ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING, 22., 2016, San Francisco. Proceedings... New York: ACM, 2016. p. 785-794.
CHENG, D.; ZOU, Y.; XIANG, S.; JIANG, C. Graph Neural Networks for Financial Fraud Detection: A Review. arXiv preprint arXiv:2411.05815, 2024.
DI GENNARO, M.; PANEBIANCO, F.; PIANTA, M.; ZANERO, S.; CARMINATI, M. Amatriciana: Exploiting Temporal GNNs for Robust and Efficient Money Laundering Detection. arXiv preprint arXiv:2506.00654, 2025.
DO, C. B.; NG, A. Y. Transfer Learning for Text Classification. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS (NeurIPS), 18., 2005. Proceedings... v. 18, p. 299, 2005.
EXPLAINABLE and fair anti-money laundering models using a reproducible SHAP framework for financial institutions. Discover Artificial Intelligence, Springer, v. 6, 2026.
FERNANDES, R. V. C.; MENDES, D. B.; CARVALHO, G. H. T. A.; FERREIRA, H. H. The VICTOR Project: Applying artificial intelligence to Brazil's Supreme Federal Court. In: Research Handbook on Big Data Law. Cheltenham: Edward Elgar, 2021. p. 304–317.
FINDING money launderers using heterogeneous graph neural networks. Expert Systems with Applications, v. 260, 2025.
HINTON, G. Reducing the Dimensionality of Data with Neural Networks. Science, v. 313, n. 5786, p. 504-507, 2006.
LIU, Fei Tony; TING, Kai Ming; ZHOU, Zhi-Hua. Isolation forest. In: IEEE INTERNATIONAL CONFERENCE ON DATA MINING (ICDM), 8., 2008, Pisa. Proceedings... Piscataway: IEEE, 2008. p. 413-422.
LUNDBERG, Scott M.; LEE, Su-In. A unified approach to interpreting model predictions. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS (NeurIPS), 30., 2017, Long Beach. Proceedings... Long Beach: NeurIPS, 2017. p. 4765-4774.
LUZ, F. et al. LeNER-Br: A Dataset for Named Entity Recognition in Brazilian Legal Text. In: INTERNATIONAL CONFERENCE ON COMPUTATIONAL PROCESSING OF THE PORTUGUESE LANGUAGE (PROPOR), 13., 2018, Canela. Proceedings... Berlin: Springer, 2018.
MIKOLOV, T. et al. Distributed Representations of Words and Phrases and Their Compositionality. In: ADVANCES IN NEURAL INFORMATION SYSTEMS (NeurIPS), 26., 2013, Lake Tahoe. Proceedings... Lake Tahoe: NeurIPS, 2013.
NUNES, R. O.; BALREIRA, D. G.; SPRITZER, A. S.; FREITAS, C. M. D. S. A Named Entity Recognition Approach for Portuguese Legislative Texts Using Self-Learning. In: INTERNATIONAL CONFERENCE ON COMPUTATIONAL PROCESSING OF THE PORTUGUESE LANGUAGE (PROPOR), 16., 2024. Proceedings... 2024.
PENNINGTON, J.; SOCHER, R.; MANNING, C. GloVe: Global Vectors for Word Representation. In: CONFERENCE ON EMPIRICAL METHODS IN NATURAL LANGUAGE PROCESSING (EMNLP), 2014, Doha. Proceedings... Doha: ACL, 2014. p. 1532-1543.
RIBEIRO, M. T.; SINGH, S.; GUESTRIN, C. Why Should I Trust You?: Explaining the Predictions of Any Classifier. In: ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING, 22., 2016, San Francisco. Proceedings... New York: ACM, 2016. p. 1135-1144.
VAN DER MAATEN, L.; HINTON, G. Visualizing Data Using t-SNE. Journal of Machine Learning Research, v. 9, p. 2579-2605, 2008.
WOLPERT,D.H.TheLackofAPriori Distinctions Between Learning Algorithms. Neural Computation, v. 8, n. 7, p. 1341-1390, 1996.

//
Contact
EVIDENCEYOURREGULATORSACCEPT
Generic scores are not defensible under BACEN Circular 3,978. We built what is.
Each alert comes with a legal citation, statistical proof, and recommended action. If you are evaluating an AML stack and care about defensibility, let’s talk.
